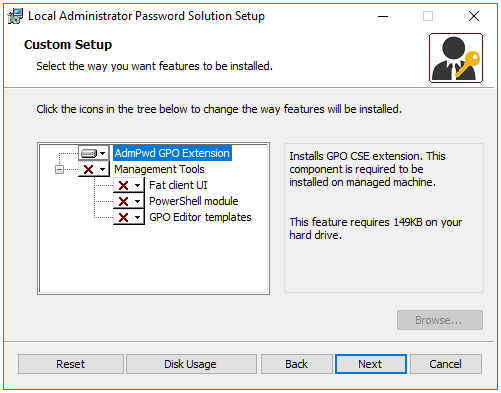
Niveau : ★★★☆☆
Suite de cette série en 5 parties. La première partie est à retrouver à cet endroit : https://thierrybtblog.wordpress.com/2023/05/26/compte-de-stockage-azure-il-y-a-beaucoup-a-dire-part-1-5/
Dans cette seconde partie, direction la bulle Général.
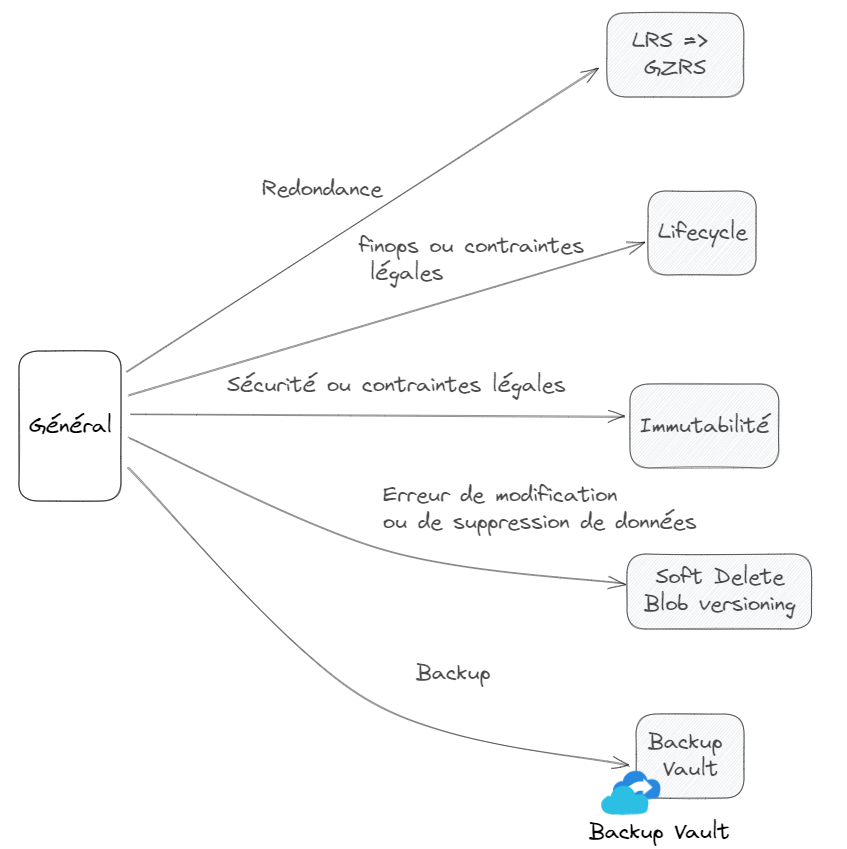
Ici, quelques unes des fonctionnalités les plus marquantes attachées aux comptes de stockage.
Premier point, la redondance du compte de stockage. Stocker, c’est bien, savoir que les données stockées sont redondées, c’est encore mieux. Ce qu’il faut retenir du stockage Azure, c’est que même dans sa version la plus économique, LRS ( Locally redundant storage), les données sont redondées. Dans un seul et même Datacenter mais dans des baies différentes. Il y a donc par défaut 3 copies (synchronisation) de vos données.
Vient ensuite la redondance de Zone ou ZRS. Les données sont synchronisées sur 3 Datacenter d’une même Zone. Par exemple, 3 Datacenter de la Zone France Central. La perte d’un Datacenter n’impactera pas l’accès aux données.
C’est ensuite une redondance Géographique GRS qui est proposée. Cette fois, les données sont présentes 3 fois sur un premier Datacenter (donc dans un modèle LRS) puis sont synchronisées dans la région paire sur un autre Datacenter dans un modèle LRS également. Ces paires de régions sont pré établies et sont disponibles ici : https://learn.microsoft.com/fr-fr/azure/reliability/cross-region-replication-azure/?WT.mc_id=AZ-MVP-5003759#azure-cross-region-replication-pairings-for-all-geographies
La région géographique France est composée de la région France Centre appairée avec la région France Sud.
Dernier niveau de redondance, un mix de la Zone et de la région appelé GZRS. SLA annoncé à … 99.99999999999999%. Pour atteindre ce niveau de disponibilité, les données sont de Zone sur la première région (ZRS) et locale sur la région appairées (LRS). La différence entre le GRS et les GZRS est donc un passage d’une paire LRS <=> LRS à une paire ZRS <=> LRS. Voici pour bien comprendre ce point une image éditeur :

Autre fonctionnalité, le Cycle de vie de la données. Toutes les données n’ont pas le même besoin de « durée » dans le temps. Mieux même, toutes n’ont pas besoin d’être accédées immédiatement (données chaudes), ou ont besoin de l’être pour une certaine durée avant de devenir des données froides ou données d’archives. C’est à dire des données pour lesquelles ont tolère un temps d’attente avant de pouvoir les consulter. Ce point est intéressant car les coûts de stockage sont différents. Et les différences sont assez conséquentes. Dans le tableau suivant, le Go stocké dans un formule Premium a un coût de 0.15$, ce même Go à un coût de 0.00099$ dans une formule Archive.

Attention, tout de même, il faut prendre en compte les coûts de réhydratation des données. C’est à dire le mécanisme qui permet à une donnée d’archive d’être « récupérée (réhydratée) pour des besoins de consultation.
Tous ces points sont automatiquement gérés par les options de Data management du compte de stockage avec la fonctionnalité Lifecycle management.

L’utilisation est simple et constituée de règles de gestion appliquées à l’échelle des blobs (tous) ou sur certains blobs seulement. Ces règles peuvent être des déplacements entre les différents niveaux de stockage, par exemple un passage de Hot à Archive ou même de la suppression pour des données qui ne sont plus nécessaires. Un exemple en image ci-dessous.

Il serait dommage de se priver de cette gestion automatique !
Avec l’option suivante, l’Immutabilité, ce sont les contraintes de sécurité ou des contraintes légales qui sont couvertes. Rendre une donnée immuable, c’est s’assurer qu’elle ne peut être supprimée / modifiée pendant un intervalle spécifié par l’administrateur. Attention, cette immutabilité est (beaucoup) plus complexe à comprendre qu’il n’y parait. Parce qu’il y a en fait deux types bien différents de données immuables.
La première est appelée Stratégie de rétention de données définie verrouillée, la seconde, Stratégie de conservation légale. Mais il y a aussi une notion d’étendue. L’immutabilité peut s’étendre à une version de blob ou à un conteneur. Tous les scénarios ne se valent pas et doivent être adaptés aux besoin.
Je liste ici quelques points clefs et je renvois à la (très) copieuse documentation éditeur sur le sujet pour une compréhension étendue : https://learn.microsoft.com/fr-fr/azure/storage/blobs/immutable-storage-overview/?WT.mc_id=AZ-MVP-5003759
Stratégies de rétention limitée dans le temps :
- Durée de conservation maximale = 400 ans
- Deux stratégies : déverrouillées, ou de tests et donc sans conformité réglementaire. Verrouillées, donc conformes, mais beaucoup plus contraignantes. Par exemple, la stratégie de conservation ne peut être revue à la baisse (possible à la hausse).
- Inclue un journal d’audit (Utilisateur, le type de commande, horodatages…etc).
Stratégies de conservation légale des données :
- Inclue un journal d’audit
- La durée de conservation légale peut être explicitement désactivée. C’est un scénario qui s’applique généralement à des fins d’investigation légale ou archivage juridique. La donnée de conservation n’est pas forcément connue par avance.
Point suivant, Soft Delete / Blob Versioning. Ou comment se sortir d’une suppression accidentelle de données.
Le Soft Delete, c’est un peu la corbeille du compte de stockage. C’est une période de rétention pendant laquelle les objets supprimés sont encore en ligne et peuvent être récupérés . Cette protection s’applique au niveau du conteneur ou au niveau de l’objet Blob. Ci-dessous, un même compte de stockage avec et sans l’affichage des blobs supprimés.

L’activation du filtre de vue (Show deleted blobs) permet d’afficher les fichiers encore retenus par la fonctionnalité. Il est ainsi possible d’exécuter un Undelete pour retrouver le fichier supprimé par erreur. Par défaut, la rétention est fixée à 7 jours mais peut s’étendre à 365 jours.
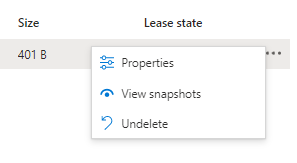
Le Blob Versioning est complémentaire du Soft Delete. Il est cette fois question de récupérer un fichier encore présent mais dans une version antérieure. Deux options … indispensables à mes yeux.
Si le Soft Delete est l’option cochée par défaut lors de la création d’un compte de stockage, ce n’est pas (encore ?) le cas pour le versioning.

Ce qu’il faut prendre en compte avec ces (belles) options, c’est qu’elles vont tout de même venir augmenter les coûts du compte de stockage. Conserver X versions d’un même fichier ou conserver un fichier supprimé pour une certain durée ne se fera évidement pas sans un coût supplémentaire.
Cette précaution apparait très clairement dans la documentation éditeur, ce ne sera donc une surprise pour personne.

Dernière fonctionnalité (dernière dans celle que j’ai choisi de présenter, il y en a tellement…), le Backup des comptes de stockage dans des coffres de type Backup Vault. J’ai volontairement déplacé cette partie en toute fin de sujet.
Parce que… je ne sais pas encore placer cette fonctionnalité comme un « vrai » besoin.
C’est un sujet « grattage » de tête pour moi. Le couple Soft Delete / Blob Versioning ne rend t-il pas la fonctionnalité de Backup des comptes de stockage « inutile ». Quels cas d’usages ne sont pas couverts, quels cas d’usages pourraient nécessiter une sauvegarde ? C’est une question ouverte à laquelle je n’ai pas la réponse. Les commentaires pour partager votre expérience sur le sujet sont les bienvenus.
Dans la prochaine partie (3/5) de cet article, il sera question de l’accès réseau et de l’exposition des comptes de stockage.